Semantic segmentation
이미지의 각 픽셀을 특정 카테고리로 분류하는 작업
→ 이미지의 픽셀 단위에서 의미론적 의미를 이해하고 분류하는 데에 중점, 객체의 인스턴스는 구분하지 않음
인스턴스 무시
- Semantic segmentation에서는 객체의 인스턴스(예: 특정 사람 또는 특정 자동차)가 아닌, 객체의 종류(즉, 카테고리)만을 고려함 → 같은 종류의 여러 객체가 구분되지 않음
- ex) 이미지에 두 명의 사람이 있을 때, 두 사람을 개별적으로 구분하는 것이 아니라, "사람"이라는 카테고리로 모든 픽셀을 분류
Semantic segmentation architectures
Fully Convolutional Networks (FCN)
- semantic segmentation 작업을 위한 첫 번째 end-to-end 네트워크 아키텍처
- 이미지의 각 픽셀을 분류하여 세밀한 의미론적 정보를 제공
- End-to-End 아키텍처
- FCN은 입력 이미지부터 최종 세그멘테이션 맵까지 모든 과정이 네트워크 내에서 직접적으로 연결된 구조를 가짐
- 중간 단계에서 별도의 데이터 전처리나 후처리 없이, 입력 이미지가 네트워크를 통과하여 최종 출력이 생성됨
- 입력 이미지 크기
- 변동 크기: FCN은 임의의 크기를 가진 이미지를 입력으로 받을 수 있음 → 이미지의 해상도가 다양한 상황에서도 유연하게 대응할 수 있음을 의미
- 출력 세그멘테이션 맵
- 해상도 유지 : 네크워크는 입력 이미지의 크기에 맞춰 세그멘테이션 맵을 출력. 원본 이미지의 크기와 동일한 해상도의 출력 맵을 생성하여, 이미지의 각 픽셀에 대해 클래스를 할당
FCN의 작동 과정
- 이미지 입력: 임의의 크기의 이미지를 네트워크에 입력
- 특징 추출: 여러 개의 합성곱 레이어를 통해 이미지의 특징을 추출
- 업샘플링: 낮은 해상도의 특징 맵을 업샘플링하여 원본 이미지 크기와 동일한 크기로 변
- 세그멘테이션 맵 생성: 최종적으로 각 픽셀에 대해 카테고리를 할당하여 세그멘테이션 맵을 출력

Fully Connected vs Fully Convolutional
- 완전 연결층(Fully connected layer): 고정된 차원의 벡터를 출력하고, 공간 좌표를 버린다
- 작동 방식: 완전 연결층에서는 입력 데이터의 모든 특징이 네트워크의 모든 뉴런과 연결됨. 결과적으로 각 뉴런은 입력 데이터의 모든 요소를 고려하여 출력을 생성한다
- 출력 형태: 고정된 크기의 벡터(1차원 배열)임
- ex) 이미지 분류 문제에서는 클래스 수에 맞춰 고정된 크기의 벡터가 출력
- 공간 좌표: 이 층은 입력 이미지의 공간적 정보를 고려하지 않는다. 즉, 입력 이미지의 위치나 형태에 대한 정보를 잃어버리며, 공간 좌표를 모두 버린다
- 용도: 주로 이미지 분류와 같은 문제에서 최종적으로 클래스 확률을 출력하는 데 사용된다
- 완전 합성곱층(Fully convolutional layer): 공간 좌표를 유지하면서 분류 맵을 출력
- 작동 방식: 합성곱 층에서는 입력 데이터의 공간적 구조를 유지하면서 특징을 추출하고, 각 픽셀 위치에서 지역적인 정보만을 고려하여 연산을 수행함
- 출력 형태: 공간 좌표를 가지는 분류 맵
- 입력 이미지의 각 픽셀에 대해 클래스 레이블을 할당한 결과를 얻을 수 있습음
- 공간 좌표: 완전 합성곱층은 입력 데이터의 공간적 정보를 보존하며, 공간 좌표를 유지한다. 이는 이미지의 세밀한 위치 정보를 고려할 수 있음을 의미함
- 용도: 주로 semantic segmentation과 같은 작업에서 사용
- 입력 이미지의 각 픽셀에 대해 클래스 레이블을 예측해야 하므로 공간적 정보를 유지하는 것이 중요
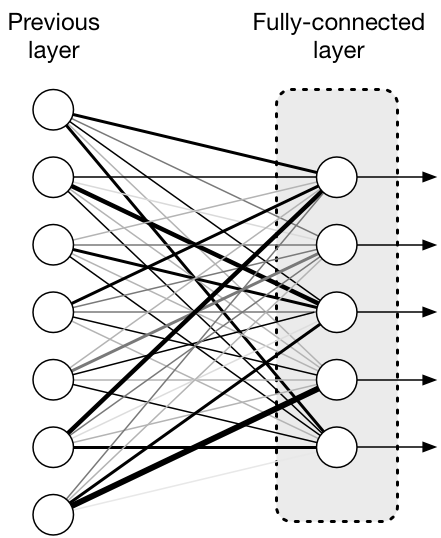
Fully Connected Layer (완전 연결층)
- 작동 방식: 완전 연결층은 입력 데이터의 모든 뉴런이 다음 레이어의 모든 뉴런과 연결
flattening단계에서 2D 이미지 데이터를 1D 벡터로 변환한 후, 완전 연결층은 이 벡터를 입력으로 받아 각 뉴런에 가중치와 편향을 적용하여 최종 출력을 생성
- 출력: 단일 벡터로서, 각 뉴런이 이미지 전체를 요약하는 정보를 출력
1x1 Convolution Layer
- 작동 방식: 1x1 합성곱층은 1x1 크기의 필터를 사용하여 각 위치의 특징 벡터를 새로운 벡터로 변환
- 공간적인 구조(위치)를 유지하면서도 각 위치의 특징을 독립적으로 변환하는 방식
- 입력 특징 맵의 각 위치에서 채널 간 결합을 수행. → 공간적 차원(H, W)은 변하지 않고, 채널 수만 변한다
- 출력: 입력 특징 맵의 각 위치에서 동일한 크기의 특징 벡터를 출력

- 입력 특징 맵이
H x W x N의 크기를 가지며, 여기서H와W는 각각 높이와 너비,N은 입력 채널 수 - 1x1 합성곱의 각 필터는
1 x 1 x N크기 → 이 필터는 1x1 크기로 공간적 정보를 다루지는 않지만, 각 위치에서N개의 입력 채널에 대해 가중합을 수행 - M개의 필터가 있다면, 각 필터는 입력 특징 맵의 각 위치(
H x W)에서 N차원 벡터와 곱해지며, 이를 통해 새로운 출력 채널을 생성함- M개의 필터를 적용한 후, 결과로 얻어지는 출력 특징 맵은
H x W x M의 크기를 가지게 된다 - 각 위치에서 N개의 입력 채널이 M개의 필터 각각에 의해 결합되므로, 출력 채널의 수는 M
- M개의 필터를 적용한 후, 결과로 얻어지는 출력 특징 맵은
1x1 합성곱층은 합성곱 특징 맵의 모든 특징 벡터를 분류
1x1 합성곱층만 많이 쌓는다고 하면?
- 예측된 스코어 맵이 많이 저해상도가 된다는 한계가 있다?
- 더 넓은 수용 영역(receptive field)을 가지기 위해, 여러 공간 풀링 레이어가 사용되기 때문?
- 업샘플링으로 스코어맵의 해상도를 높여 해결 가능!
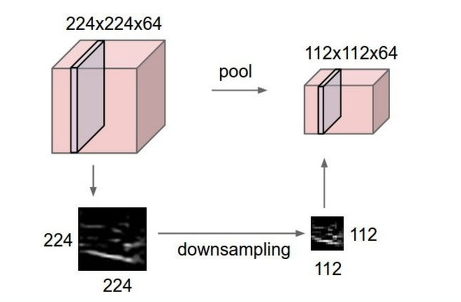
피쳐 맵 자체가 이미 해상도가 많이 낮아지고 피쳐 디멘션만 커진 구조
풀링 레이어나 스트라이드가 있는 컨볼루션을 거치면서 이미지의 중심 피쳐만 두고 해상도가 감소하게 되는데, 이 1 x 1 컨볼루션은 해상도에 영향을 주지 않아서 결과적으로 스코어 맵이 저해상도인 채로 나오게 된다?
업샘플링 Upsampling
작은 활성화 맵(activation map)을 원본 이미지 크기로 확장하는 과

- 언풀링(Unpooling): 언풀링은 주로 풀링 층에서 사용된 인덱스 정보를 기반으로 원래 크기로 복원하는 방법
- 최대 풀링(max pooling) 후에 언풀링을 사용하면, 최대 값이 있었던 위치에 다시 값을 복원.
- 그러나 이는 비선형적인 방법이기 때문에, 고해상도의 세밀한 세부 사항을 복원하기에는 한계가 있을 수 있음
- 전치 합성곱(Transposed Convolution): 전치 합성곱, 또는 업샘플링 합성곱(upsampling convolution)은 입력 데이터에 대한 합성곱 연산을 역으로 적용하는 방법
- 이미지의 해상도를 증가시키며, 필터를 사용하여 고해상도 이미지를 생성
- 전치 합성곱은 대개 많은 파라미터와 계산량을 필요로 하지만, 고해상도의 세밀한 정보를 생성하는 데 효과적
- 업샘플링과 합성곱(Upsample and Convolution): 먼저 업샘플링을 통해 입력 데이터의 크기를 늘리고, 그 후에 합성곱을 적용하여 세부 사항을 보강하는 방식
- 전치 합성곱보다 연산이 덜 복잡할 수 있으며, 보다 제어된 방식으로 해상도를 증가시킬 수 있음
FCN의 특징
- FCN은 빠르다. 다른 작업으로 만든 구성 요소에 의존하지 않는 종단 간 (end-to-end) 아키텍처를 갖추고 있다는 점에서 빠름
- FCN은 이미지 분할과 같은 작업을 수행할 때, 입력 이미지에 대해 전체적으로 합성곱 연산을 적용하여 직접 예측을 수행함.
- 전통적인 방법에서 필요했던 여러 전처리 및 후처리 단계가 줄어들어 모델의 속도가 빠르다! 모든 연산이 네트워크 내부에서 이루어지기 때문에, 각 구성 요소가 독립적으로 조정되거나 설계되지 않아도 됨
- FCN은 정확하다. 특징 표현(feature representation)과 분류기(classifier)가 함께 최적화된다는 점에서 정확도가 높음
- FCN은 네트워크가 입력 이미지를 처리하고, 다양한 수준의 특징을 추출하며, 최종적으로 분류를 수행
- 특징 표현과 분류가 동시에 학습되고 최적화되기 때문에, 이미지의 세부 사항을 잘 반영할 수 있어서 더 정확한 예측 가능
- 전통적인 방법에서처럼 별도로 특징 추출과 분류기를 훈련시키는 것과 비교하여, 이 통합된 접근 방식이 더 높은 정확도를 제공함
U-Net
- 진행 방식이 U 모양이라 U-Net
- fully convolution networks 기반으로 구축되어 FCN의 특성을 공유함
- 입력 이미지로부터 픽셀 단위의 출력 맵을 예측하는 데에 주력
- 수축 경로(contracting path)에서 얻은 특징 맵들을 연결하여 밀집된 맵을 예측
- FCN의 스킵 연결과 유사
- 더 정밀한 분할 결과를 생성함
- 수축 경로(contracting path)와 확장 경로(expanding path)로 구성된 대칭적인 아키텍처
- 수축 경로에서는 이미지를 점점 더 작은 해상도의 특징 맵으로 압축하면서 중요한 정보(특징)를 추출하고, 확장 경로에서는 이 특징 맵들을 다시 큰 해상도로 확장하며 밀집된 예측 맵(dense map)을 생성
- 수축 경로에서 생성된 특징 맵들을 확장 경로로 전달할 때, 중간중간의 특징 맵들을 직접 연결(concatenation)하는 방식이 사용 → FCN에서의 스킵 연결(skip connections)과 유사
- 이를 통해 더 정밀한 이미지 분할 결과를 얻을 수 있고, U-Net은 특히 의료 영상 처리나 위성 이미지 처리와 같은 영역에서 성능이 좋다

수축 경로(contracting path)
- 시작점에서 최저점까지 우하향
- Conv Layers + Pooling: 먼저, 입력 이미지는 여러 개의 합성곱(Convolution) 층과 최대 풀링(Max Pooling) 층을 거쳐 점차적으로 해상도가 줄어들고, 특징이 추출
- 이미지가 점점 작아지면서 더 많은 채널을 가지는 특징 맵들이 생성
- 이 경로는 FCN의 다운샘플링(downsampling) 단계와 유사하며, U의 왼쪽 절반에 해당
최저점 (Bottleneck)
- 수축 경로의 마지막 단계는 해상도가 가장 낮은 특징 맵을 생성하는 부분
- 네트워크의 가장 깊은 레벨이며, U의 바닥에 해당
- 여기서도 합성곱과 풀링이 적용
- 수축 경로의 마지막 단계는 해상도가 가장 낮은 특징 맵을 생성하는 부분
확장 경로(expanding path)
- Upconv Layers: 확장 경로에서는 반대로 해상도가 다시 커지도록 업샘플링(Upsampling)을 수행
- 업샘플링: 입력을 확장해서 더 높은 해상도의 출력으로 변환하는 과정으로, 풀링의 반대 역할
- 이 경로는 U의 오른쪽 절반에 해당
- Upconv Layers: 확장 경로에서는 반대로 해상도가 다시 커지도록 업샘플링(Upsampling)을 수행
스킵 연결 (Skip Connections)
- 수축 경로에서 생성된 특징 맵들이 확장 경로의 대응되는 단계로 직접 연결(concatenate)된다
- 스킵 연결은 정보를 잃지 않고 잘 보존할 수 있게 해어, 최종 출력에서 더 정확한 분할 결과를 얻을 수 있게 해줌
최종 출력 (Final Output)
- 업샘플링된 특징 맵은 다시 합성곱 층을 통해 최종 분할 결과, 즉 각 픽셀이 어떤 클래스에 속하는지를 나타내는 밀집된 맵으로 변환
'Study - AI > Computer Vision' 카테고리의 다른 글
| Computational Imaging (0) | 2025.01.16 |
|---|---|
| Object Detection & R-CNN (0) | 2025.01.15 |
| ViT & GAN (0) | 2025.01.14 |
| CNN (Convolution Neural Network) (0) | 2025.01.13 |