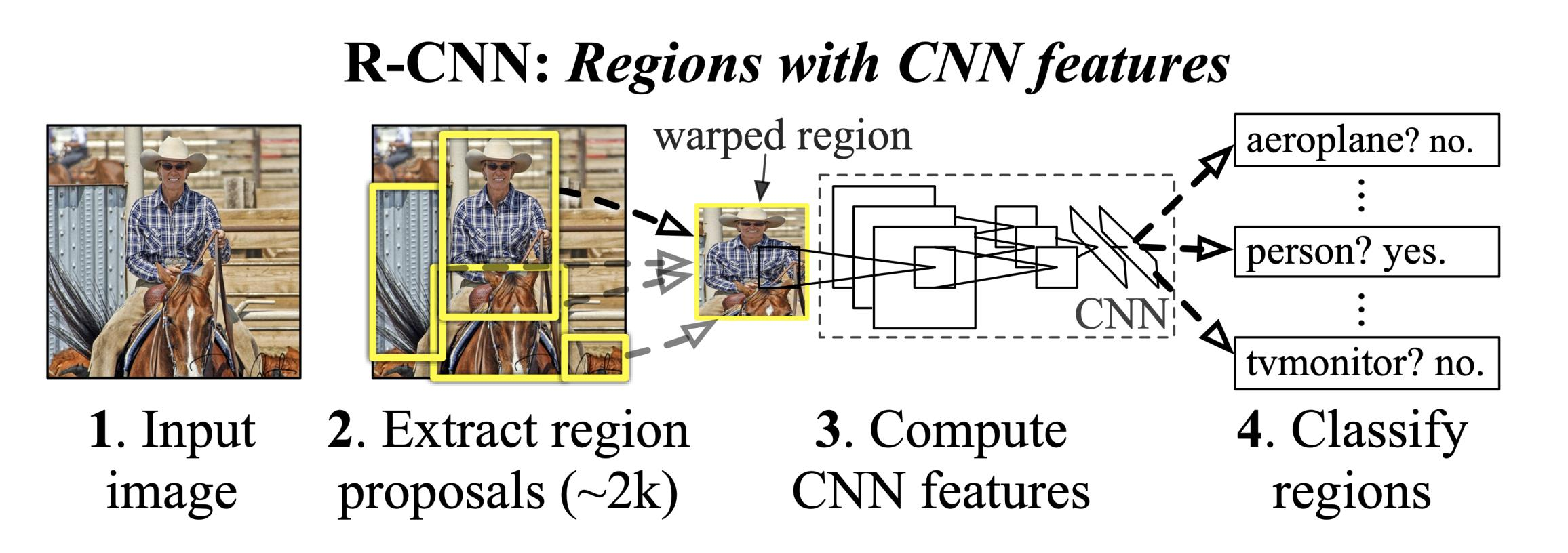
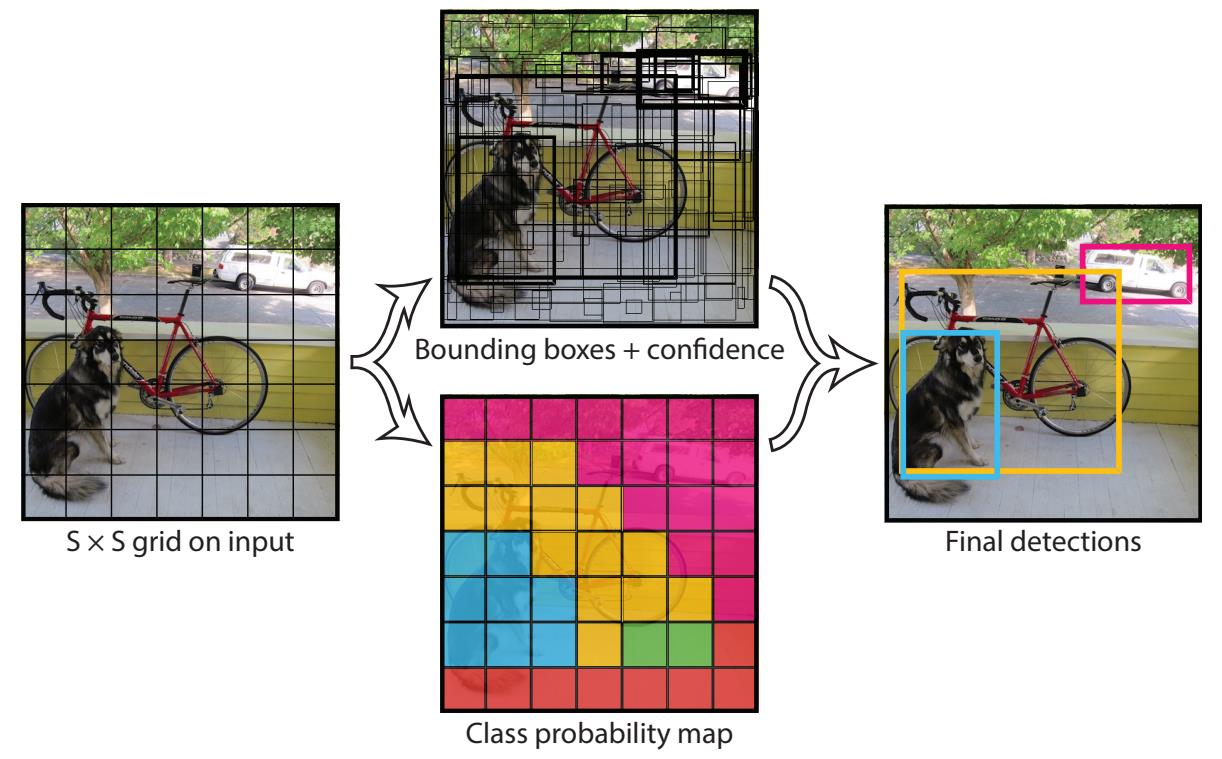
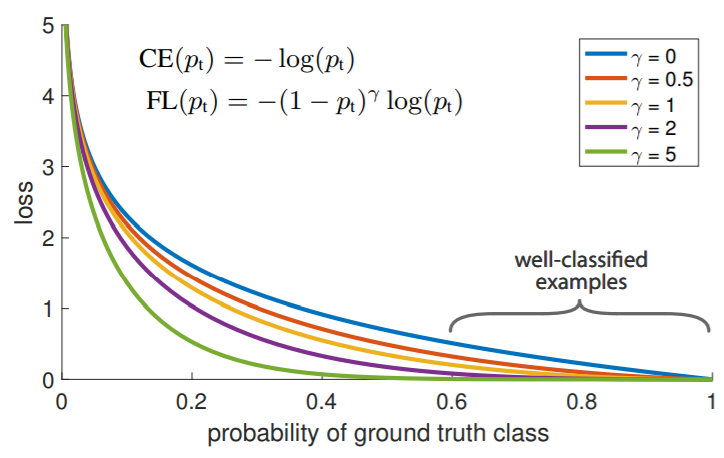
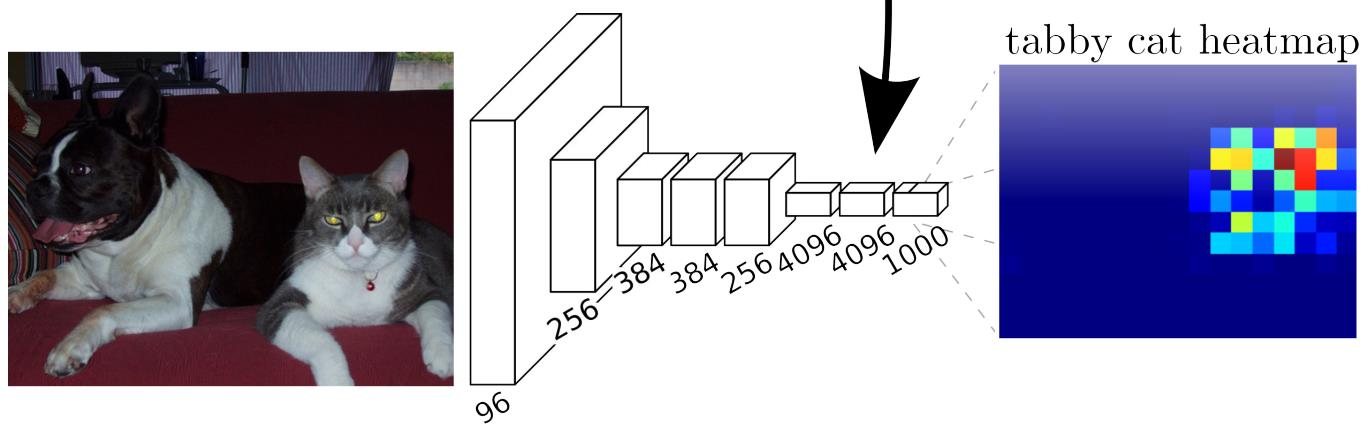
Computational Imaging
Computational Photography
- 이미지 생성과 처리에 컴퓨팅 기술을 추가하는 분야
- 기존의 사진 촬영 방법에 컴퓨터 알고리즘을 결합하여 새로운 방식으로 이미지를 생성하고 개선하는 방법을 제시
In-Camera Pipeline (카메라 내 파이프라인)
In-camera pipeline은 카메라가 이미지를 캡처할 때 처리하는 단계
- 센서 데이터 캡처: 카메라 센서가 빛을 감지하여 디지털 신호로 변환
- 원시 데이터 처리: 센서에서 받은 원시 데이터를 처리하여 이미지로 변환
- 노이즈 제거: 이미지에서 노이즈를 제거하여 품질을 향상시킴
- 화이트 밸런스 조정: 색 온도를 조정하여 자연스러운 색상으로 만듦
- 노출 조정: 밝기를 조절하여 최적의 노출을 제공
- 샤프닝 및 색상 보정: 이미지의 선명도와 색상을 조정
Computational Photography: Adding Computation into the Imaging Pipeline
Computational photography는 전통적인 카메라 파이프라인에 알고리즘과 컴퓨터 비전 기술을 추가하여, 이미지 생성과 처리를 향상시키는 접근 방식인데, 이는 단순히 하드웨어의 성능을 개선하는 것을 넘어서, 소프트웨어적으로 이미지를 처리하는 방법도 변화시킴
- HDR (High Dynamic Range) Imaging: 다양한 노출로 촬영된 여러 이미지를 결합하여 넓은 범위의 명암을 표현할 수 있는 이미지를 생성
- Image Stitching: 여러 장의 사진을 합쳐서 넓은 범위의 파노라마 이미지를 만듦
- Computational Refocusing: 사진을 찍은 후, 초점을 조절할 수 있는 기술
- Low-light Enhancement: 어두운 환경에서도 선명하고 밝은 이미지를 생성하기 위해 복잡한 알고리즘을 사용
응용 분야
- Low light image enhancement / Denoising
- Super-resolution
- Deblurring
- High dyanmic range imaging
- Stylization
- Colorization 흑백 → 컬러
- 이미지 복원 (Image Restoration): 손상된 이미지를 복구하거나, 노이즈를 제거하고 화질을 개선하는 작업
- 이미지 개선 (Image Enhancement): 이미지를 더 선명하고, 색상과 밝기를 조정하여 시각적으로 더 매력적으로 만드는 작업
- 3D 모델링: 2D 이미지에서 3D 형태를 재구성하여, 가상 현실이나 증강 현실에서 활용할 수 있는 3D 모델을 생성
Training data in computational imaging
Case 1 : Image Denoising
- 이미지의 노이즈를 제거하여 선명하고 깨끗한 이미지를 복원하는 과정
- 노이즈는 이미지 품질을 저하시키고, 특히 저조도 환경에서 더 두드러지게 나타날 수 있음
Camere noise
- Pre-ADC Noise:
- 이미지를 디지털로 변환하기 전, 즉 아날로그 신호 단계에서 발생하는 노이즈를 의미 → 저조도 조건에서는 이 노이즈가 더욱 두드러짐
- Signal-dependent Noise (신호 의존 노이즈)
- Photon shot noise는 광자(photon) 수의 변동으로 인해 발생하는 노이즈
- 이는 양자화(quantization)와는 관련이 없으며, 물리적 현상으로 인해 생기는 노이즈
- 저조도 환경에서는 광자가 적게 들어오기 때문에, 광자 수의 변동이 더 큰 영향을 미치게 되어 노이즈가 증가함
- 이 노이즈는 신호 강도에 비례하여 발생하기 때문에, 밝은 부분에서는 노이즈가 덜 눈에 띄지만, 어두운 부분에서는 더 두드러지게 된다
- Photon shot noise는 광자(photon) 수의 변동으로 인해 발생하는 노이즈
- Signal-Independent Noise (신호 독립 노이즈)
- Read Noise
- Read noise는 이미지 센서가 신호를 읽을 때 발생하는 노이즈
- 센서의 전기적 특성에서 비롯되며, 신호의 강도와 관계없이 일정한 양의 노이즈를 추가
- 이 노이즈는 센서의 읽기 과정에서 항상 발생하므로, 저조도에서도 일정하게 나타난다
- Quantization Noise
- Quantization noise는 아날로그 신호를 디지털로 변환할 때 발생하는 노이즈
- 변환 과정에서 아날로그 신호의 연속적인 값을 디지털 값으로 변환하면서 발생하는 오차
- 디지털 비트 깊이와 관련이 있으며, 비트 깊이가 낮을수록 더 많은 양의 노이즈가 발
- Read Noise
Noise Model
- 이미지에서 발생하는 노이즈를 수학적으로 표현하는 방법
- Gaussian noise는 가장 일반적으로 사용되는 노이즈 모델로, 이미지의 품질을 저하시킬 수 있음
Gaussian Noise
- 정규 분포를 따르는 노이즈로 통계적으로 가장 많이 발생하며 실제 상황에 잘 맞는 모델임
- 수학적으로 단순하고 분석 및 처리가 쉬워서 가장 널리 사용되는 노이즈 모델
Mathematical Model
- 노이즈 모델:
- 이미지의 노이즈를 수학적으로 표현할 때, 노이즈 없는 원본 이미지 x에 가우시안 노이즈 n이 추가되어 손상된 이미지 y를 형성
y = x + n- y = 노이즈가 추가된 이미지
- x = 노이즈가 없는 원본 이미지
- n = 가우시안 노이즈
- Gaussian Noise Distribution
- Gaussian noise n은 정규 분포를 따름
- 즉, 노이즈 n은 평균이 0이고, 분산이 $σ^{2}$인 정규 분포 N(0, $σ^{2}$)를 따른다
- 정규 분포: n ~ N(0, $σ^{2}$)
- $σ^{2}$ = 노이즈의 분산 → 노이즈의 강도를 결정. 분산이 클수록 노이즈의 강도가 강해진다
가우시안 노이즈의 확률 밀도 함수

- $σ^{2}$ = 노이즈의 분산, n = 노이즈 값
Case 2 : Image super resolution
Image super resolution
- Super resolution(초해상도)은 저해상도 이미지를 입력으로 받아 고해상도 이미지로 복원하는 기술
- 이미지의 디테일을 향상시키고, 픽셀 수를 증가시켜 더 선명하고 정밀한 이미지를 생성하는 것을 목표로 함
Synthetic data generation
- 실제 데이터를 사용하지 않고, 특정 목적에 맞는 인공 데이터를 생성하는 과정
- 기계 학습이나 컴퓨터 비전에서 훈련 데이터를 확보하기 어려울 때 많이 사용
- 고해상도 자연 이미지 수집
- 먼저, 고해상도 이미지들을 수집 → 이러한 이미지들은 원본 데이터로 사용되며, 이후 저해상도 이미지를 생성하기 위한 출발점
- 저해상도 이미지 생성
- 고해상도 이미지를 다운샘플링(down-sampling)하여 저해상도 이미지를 생성
- 다운샘플링은 이미지의 픽셀 수를 줄여 해상도를 낮추는 것
- 이는 다양한 방법으로 수행될 수 있지만, 일반적으로 양큐빅 보간법(bicubic interpolation)과 같은 보간 기법이 사용된
- 고해상도 이미지를 다운샘플링(down-sampling)하여 저해상도 이미지를 생성
주의점: 다운샘플링의 한계
- 다운샘플링의 비정확성:
- 다운샘플링은 실제 카메라가 이미지를 캡처할 때 수행하는 모든 복잡한 과정을 정확히 모사하지 않음.
- 저해상도 이미지로 변환되면서 고해상도 이미지의 중요한 피쳐를 온전히 반영하지 않게 될 수 있다는 것이 단점이라는 말!
- ex) 카메라에서 발생하는 노이즈, 렌즈의 비네팅, 색상 왜곡 등은 단순한 수학적 보간으로는 재현할 수 없음
- 다운샘플링은 실제 카메라가 이미지를 캡처할 때 수행하는 모든 복잡한 과정을 정확히 모사하지 않음.
- 바이큐빅(양큐빅) 보간법 (Bicubic Interpolation)
- 입력 이미지의 16개 인접 픽셀을 고려하여 새로운 픽셀 값을 계산
- 그러나 이는 카메라의 실제 물리적 동작을 정확히 반영하지 않기 때문에, 원본 고해상도 이미지의 특성을 모두 보존하지 못할 수 있
RealSR
- RealSR는 Super Resolution(SR) 모델을 훈련시키기 위해, 보다 현실적인 훈련 데이터를 생성하는 방법 → 실제 카메라의 이미징 시스템을 모사한다!
- 기존의 단순한 다운샘플링 방식 대신, 실제 카메라의 작동 방식을 모사하여 보다 현실적인 저해상도-고해상도 이미지 쌍을 만들어낸다
- 실제 카메라를 이용해서 최대한 실제적인 데이터 취득을 시도함
실제 DSLR 카메라의 이미징 시스템을 얇은 렌즈 모델(Thin Lens)로 모사함.
→ 카메라 렌즈의 물리적 특성을 수학적으로 표현하며, 이를 통해 현실적인 저해상도 이미지를 생성
얇은 렌즈 모델은 렌즈의 초점 거리(f), 물체와 렌즈 사이의 거리(u), 이미지 센서와 렌즈 사이의 거리(v) 간의 관계를 나타내는 수식으로 정의

- f: 렌즈의 초점 거리
- u: 물체와 렌즈 사이의 거리
- v: 이미지 센서와 렌즈 사이의 거리

실제 카메라에서 발생하는 포커싱, 왜곡, 심도, 노이즈 등 다양한 물리적 효과를 고려하여 보다 실제적인 저해상도 이미지를 생성할 수 있다
RealSR의 장점
- 현실성 향상: 실제 카메라의 이미징 시스템을 모사하여, 더 현실적인 저해상도 이미지를 생성할 수 있음 → SR 모델의 실제 성능을 높이는 데 도움이 됨
- 정밀한 훈련 데이터: 얇은 렌즈 모델을 사용하여 생성된 훈련 데이터는 기존 방법보다 정밀하고 세부적인 특징을 반영 → 모델이 더 나은 화질을 복원할 수 있게 됨
저해상도(LR)와 고해상도(HR) 쌍을 만듦 → 단순히 해상도 차이만 두고 생성하는 것보다, 카메라의 초점 거리(focal length)를 다르 촬영하면, 더 현실적인 차이를 반영할 수 있게 된다
- 초점 거리가 짧을수록(광각 렌즈) 더 넓은 영역이 촬영되지만, 디테일이 상대적으로 줄어듦
- 초점 거리가 길수록(망원 렌즈) 더 좁은 영역을 확대하여 촬영하지만, 더 많은 디테일을 포착
Case 3 : Image deblurring
- deblurring은 블러(blur)로 인해 손상된 이미지를 복원하는 과정을 의미
- 블러는 이미지가 흐릿해지거나 왜곡되는 현상으로, 주로 카메라 흔들림이나 객체의 움직임으로 인해 발생
- Motion Blur (모션 블러):
- 원인: 카메라가 흔들리거나 촬영하는 동안 객체가 움직이는 경우 발생
- 특징: 블러가 이미지에서 특정 방향으로 길게 늘어나는 현상 등
- ex) 움직이는 차량의 바퀴가 길게 늘어나 보임… 샤샤샥
- Lens Blur (렌즈 블러):
- 원인: 초점이 맞지 않아 발생 (지금 과정에서는 자세히 안 다룬다!)
- 특징: 렌즈의 초점이 맞지 않아 이미지의 특정 부분이 흐릿해지거나 부드럽게 나타남
Deblurring 과정
- 블러 모델링
- 블러 유형 파악: 먼저, 이미지에서 발생한 블러의 유형을 파악 → 모션 블러의 경우, 블러의 방향과 길이를 모델링할 수 있어야 함
- 블러 커널 추정: 블러를 복원하기 위해, 블러의 커널(kernel)을 추정 → 커널은 블러가 적용된 방식과 패턴을 나타낸다
- 복원 알고리즘 적용:
- 역블러 필터: 블러 커널을 알고 있거나 추정한 경우, 역블러 필터(deblurring filter)를 사용하여 블러를 제거
- 최적화 기술: 역블러 필터를 적용하기 전에, 최적화 기술을 사용하여 블러 커널을 정확히 추정 → 이는 이미지의 선명도를 복원하는 데 중요
- 후처리:
- 노이즈 제거: 디블러링 과정에서 노이즈가 추가될 수 있으므로, 노이즈를 줄이기 위한 후처리 단계를 포함할 수 있음
- 세부 조정: 복원된 이미지의 품질을 개선하기 위해 추가적인 세부 조정을 수행
Deblurring 방법
- 데이터 기반 방법:
- 딥러닝 접근법: CNN(Convolutional Neural Networks)이나 GAN(Generative Adversarial Networks)을 활용하여 블러를 제거하고 선명한 이미지를 복원
- 모델 기반 방법:
- 복원 필터링: 전통적인 접근법으로, 복원 필터(restoration filters)를 사용하여 블러를 제거하는 방법 → 블러의 커널을 알고 있는 경우 효과적
- 주파수 도메인 방법:
- 푸리에 변환: 이미지의 주파수 도메인에서 블러를 제거하는 방법으로, 블러의 주파수 특성을 분석하고 이를 반전시켜 복원
고속 촬영 카메라를 사용한 현실적인 데이터 획득 방법
- 여러 개의 짧은 노출 프레임을 촬영하여 긴 노출 효과를 만들어내고, 이를 처리하여 실제적인 블러를 얻는 기술
- 블러를 시뮬레이션하고 이해하는 데에 유용
- 고속 촬영 카메라 사용:
- 고속 촬영 카메라(예: GoPro)를 사용하여 매우 빠른 프레임 속도로 이미지를 촬영한다. 이 카메라는 짧은 노출 시간 동안 많은 수의 프레임을 캡처할 수 있다.
- 짧은 노출 프레임 촬영:
- 카메라는 짧은 노출 시간을 사용하여 이미지의 선명한 장면을 여러 번 촬영한다. 이로 인해 각 프레임이 선명한 세부 사항을 담고 있지만, 블러가 없는 상태로 캡처된다
- 긴 노출 이미지 생성:
- 촬영된 짧은 노출 프레임들을 합산하여 긴 노출 이미지를 생성한다. 이 과정에서 여러 프레임의 정보가 합쳐져서 블러가 포함된 이미지를 만든다
- 비선형 카메라 응답 함수(CRF) 적용:
- 생성된 블러 이미지에 대해 비선형 카메라 응답 함수(Camera Response Function, CRF)를 적용하여 신호를 픽셀 값으로 변환한다. CRF는 카메라 센서의 비선형 응답을 보정하는 함수
- 블러 축적 과정:
- 여러 개의 짧은 노출 프레임을 축적하여 긴 노출 효과를 얻는 이 과정에서 이미지의 움직임이나 초점 불량에 의한 블러가 자연스럽게 반영된다
RealBlur
- 이미지 복원 및 슈퍼 해상도(Super-Resolution) 분야에서 사용되는 실제적인 블러(Blur) 데이터 생성 방법
- 실제 이미지에서 블러를 시뮬레이션하여 훈련 데이터를 생성하는 데 중점
- RealBlur의 목표는 실제적인 블러 현상을 모델링하여 훈련 데이터를 생성하는 것으로, 이 훈련 데이터는 블러를 포함한 이미지와 블러가 없는 원본 이미지를 포함하여, 모델이 블러를 효과적으로 제거할 수 있도록 학습시키는 데 사용한다
'Study - AI > Computer Vision' 카테고리의 다른 글
| Object Detection & R-CNN (0) | 2025.01.15 |
|---|---|
| Semantic Segmentation (0) | 2025.01.14 |
| ViT & GAN (0) | 2025.01.14 |
| CNN (Convolution Neural Network) (0) | 2025.01.13 |