Object Detection 개인적으로 헷갈리기 쉬운 내용들
Detector 구조의 구성 요소
- CornerNet
- Anchor-free 방식의 one-stage detector
- RPN을 사용하지 않음
- [Input → Backbone → Dense prediction] 구조
- Fast R-CNN
- RPN이 없음 (selective search 사용)
- Neck 구조가 없음
- [Input → Backbone → Sparse prediction] 구조
- YOLO
- One-stage detector로 RPN 없음
- [Input → Backbone → Dense prediction] 구조
- Sparse prediction 대신 Dense prediction 사용
- Faster R-CNN + FPN
- Input: 입력 이미지
- Backbone: 특징 추출 (ResNet 등)
- Neck: FPN (Feature Pyramid Network)
- RPN: Region Proposal Network
- Sparse prediction: RoI Head에서의 예측
- 문제에서 제시한 5가지 구성요소를 모두 포함
- RetinaNet
- One-stage detector로 RPN 없음
- [Input → Backbone → Neck → Dense prediction] 구조
- Focal loss를 사용하는 것이 특징
YOLO v1 loss

- 첫 번째 부분
- (x,y) 좌표와 (w,h) 크기에 대한 loss
- 박스의 위치와 크기를 예측하는 localization loss
- 두 번째 부분
- 객체가 있을 확률(C)에 대한 loss
- confidence score를 예측하는 confidence loss
- 세 번째 부분
- 클래스 확률(p)에 대한 loss
- 객체의 클래스를 분류하는 classification loss
localization / confidence / classification
- 수식의 순서와 정확히 일치
- 각 loss의 역할을 정확히 반영
Object detection evaluation metric
- FLOPS (Floating Point Operations Per Second)
→ Object detection에서 사용되는 metric- 모델의 연산량을 측정
- 모델의 효율성 평가
- 실제 구현 시 중요한 고려사항
- FPS (Frames Per Second)
→ Object detection에서 사용되는 metric- 실시간 처리 속도 측정
- 초당 처리할 수 있는 프레임 수
- 실시간 응용에서 중요한 지표
- FID (Fréchet Inception Distance)
→ Object detection metric이 아님- GAN 모델의 성능 평가에 사용되는 지표
- 생성된 이미지의 품질 평가
- Object detection과는 관련이 없음
- mIoU (mean Intersection over Union)
→ Object detection에서 사용되는 metric- 예측 박스와 실제 박스의 겹침 정도 측정
- 위치 예측의 정확도 평가
- Segmentation에서도 사용됨
- mAP (mean Average Precision)
→ Object detection에서 사용되는 metric임- 검출 정확도를 종합적으로 평가
- PR 커브의 면적 계산
- 가장 널리 사용되는 평가 지표
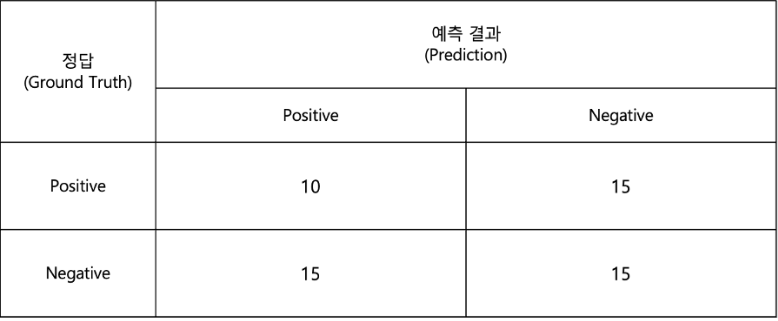
Precision & Recall
- 먼저 각 요소를 파악
- Ground truth (실제 고양이): 4마리
- Positive prediction (빨간 박스): 4개
- True Positive (TP): (실제 고양이를 맞게 예측)
- False Positive (FP): (고양이가 아닌 것을 고양이로 예측)
- False Negative (FN): (놓친 고양이)
- 총 8개를 검출하고 그 중 3개가 옳은 검출이므로, precision = 3/8 = 0.375
- 총 4개의 GT가 있고 그 중 3개를 검출했으므로, recall = 3/4 = 0.75
Corner Pooling
CornerNet에서는 corner를 결정하기 위해 corner pooling이라는 방법을 사용한다. 그림과 같은 두 개의 feature maps의 일부가 주어지고 각각에 대해 수직, 수평방향으로 pooling을 할 때, corner pooling의 output map에서 (a), (b), (c), (d) 에 들어갈 숫자의 순서로 옳은 것
Corner pooling은 각 feature map에 대해 horizontal pooling, vertical pooling을 수행한 후 element-wise summation을 수행한다.
DarkNet Output
YOLO v1에서는 입력 이미지를 SxS의 grid cell로 분할하며, 각 cell마다 B개의 bounding box와 confidence score, 그리고 각 cell마다 C개의 class에 대한 conditional class probabilities를 예측한다. Input image의 shape은 288x288x3이며 S=12, B=3, C=100일 경우, YOLO v1 DarkNet의 최종 output으로 나오는 feature map의 shape (W, H, C)이다. 이 때 W+H+C의 값으로 옳은 것
주어진 조건
- Input image: 288x288x3
- Grid cell: SxS (S=12)
- 각 cell당 B개의 bounding box와 confidence score (B=3)
- 각 cell당 C개의 클래스에 대한 확률 (C=100)
Output shape 계산
각 Grid cell당 예측해야 하는 값
- B개의 bounding box 좌표 (x,y,w,h): 4×B
- B개의 confidence score: 1×B
- C개의 클래스 확률: C
전체 계산
- Cell당 필요한 값 = (4+1)×B + C
- = 5×3 + 100
- = 15 + 100
- = 115
최종 output shape
- W = H = S = 12 (grid size)
- C = 115 (각 cell당 예측값)
- 따라서 12×12×115 = 139
YOLO v1은 각 grid cell별로 B개의 bounding box(4개의 좌표)와 confidence score, 그리고 C개의 conditional class probabilities를 예측한다. 즉, 각 cell마다 B5+C 개의 예측값이 나오기 때문에 DarkNet의 최종 output shape은 (S, S, (B5+C))이다. 따라서 문제에서 주어진 것처럼 S=12, B=3, C=100일 경우 output shape은 (W, H, C) = (12, 12, (3*5+100)) = (12, 12, 115)이며, W+H+C = 12+12+115 = 139이다
Computing AP
PR Curve를 그리기 위한 표를 보고 실제 AP가 어떻게 계산되는지 직접 계산해 보자.
1x0.2 + 0.8x0.2 + 0.71x0.1 + 0.6x0.1 = 0.49
'Study - AI > Object Detection' 카테고리의 다른 글
| Advanced Object Detection (0) | 2025.04.02 |
|---|---|
| EfficientNet & EfficientDet (0) | 2025.02.04 |
| Neck (0) | 2025.01.27 |
| Object Detection Library : MMDetection, Detectron (0) | 2025.01.24 |
| Object Detection Overview (0) | 2025.01.17 |